On Wikidata’s fifth birthday, we (the Gene Wiki team) offer our hearty congratulations!! It is amazing what has been achieved in such a short timespan. Wikidata has basically given us – and the larger research community – the gift of not having to maintain a core knowledge infrastructure. It has been taken care of (i.e. millions of SPARQL queries daily), so the research community can now focus on its core task, doing research.
Our project – the Gene Wiki project – started in 2008 with the objective to seed Wikipedia with high quality basic biomedical facts with the goal of crowdsourcing a gene-specific review article for every human gene. With the birth of Wikidata in 2012, we shortly after shifted our focus from Wikipedia to Wikidata. On Oct 6, 2014, we had our first milestone: all human genes had entities in Wikidata.
"The human genome is done" nice message from @andrawaag 🙂 All human genes now have entities in @wikidata. e.g. https://t.co/HDrijfxDTT
— Benjamin Good (@bgood) October 6, 2014
Since then, we have continued enriching Wikidata with not only gene annotations from other species, but also extended the coverage to related concepts such as diseases, drugs, chemical compounds and other related concepts. We have developed a python library (Wikidata Integrator), which started as a biomedical library but is now applied in other domain areas.
We view the current landscape of biomedical data in Wikidata as basically consisting of three layers. The first layer is those resources which our team has directly loaded. We have focused on resources that are the most commonly used by researchers to form a solid foundation of biomedical knowledge. The second layer is formed by partner organizations with whom we’ve collaborated to help bring their resources into Wikidata. These partners bring key new data types, including information on genetic variants (from CIViC) and on biological pathways (from Wikipathways and Reactome). And finally, we are perhaps most excited when we discover efforts that are completely independent in origin but highly synergistic in our mission. This group includes James Hare’s effort to load environmental exposures from the CDC, and the amazing Wikicite team for loading bibliographic data from the scientific literature.
The sum total of all this work is a richly interconnected network of open biomedical knowledge. And this network enables us to ask and answer an impressively diverse set of biomedical questions (a growing list is documented at https://www.wikidata.org/wiki/User:ProteinBoxBot/SPARQL_Examples).
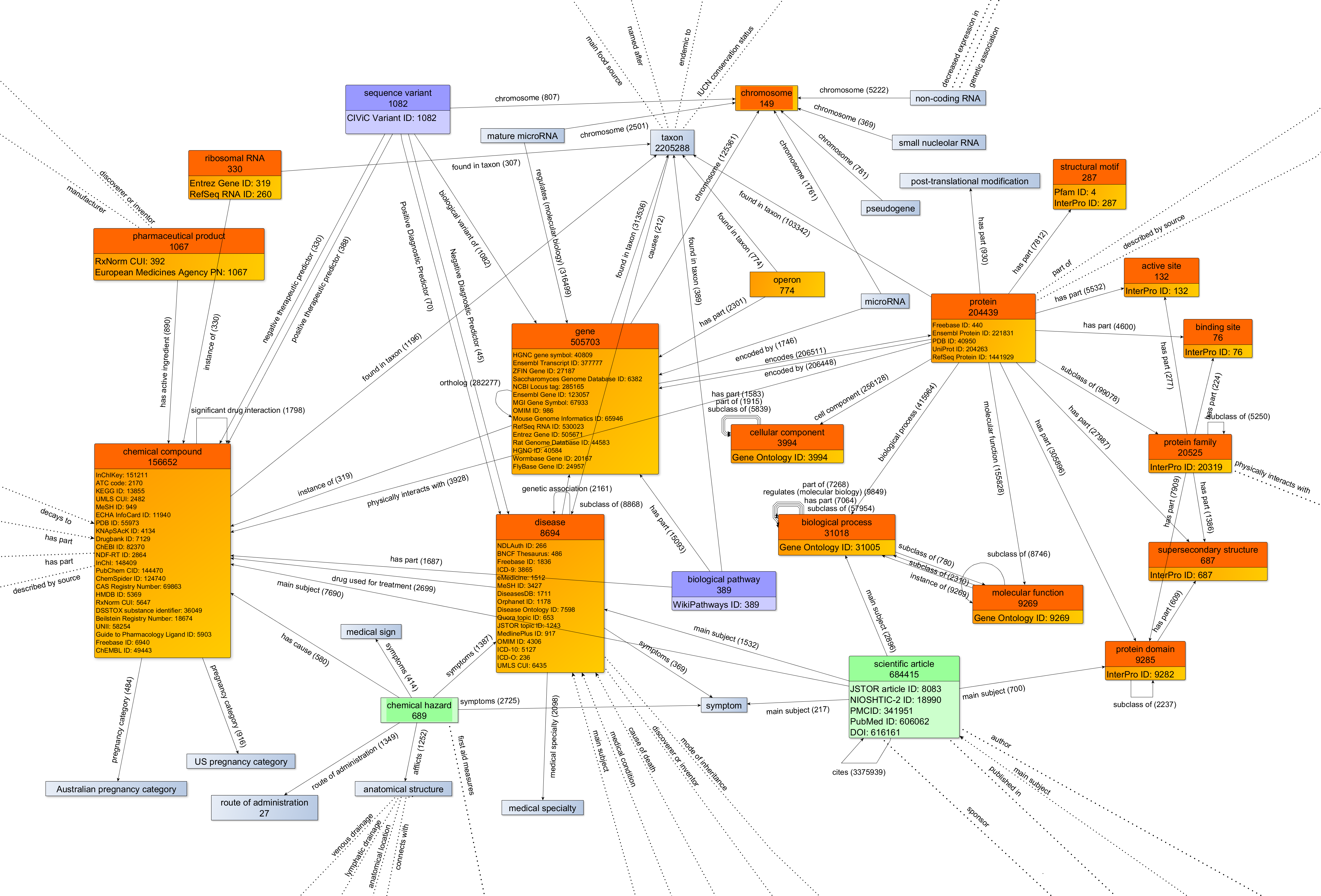
The genewiki landscape with its three layers.
Looking ahead and as a birthday present, we can lift a corner of the veil on our imminent developments.
To improve the robustness we are developing stronger feedback loops to experts curating primary sources. These feedback loops are based on validation reports such as the already existing constraint violations, but we are also looking into more complex constraint patterns where multiple statements are validated together using Shape Expressions. Currently, our bots are running on a continuous integration platform called Jenkins, we are working towards more automation of our efforts, such as driving the feedback loops and quality control.
We are excited to continue our work to make Wikidata the most comprehensive hub for open and linked biomedical data!